Page Last Updated: April 8, 2026
HBCD Data Processing Workflows🔗
Clear objectives & scope
Click to learn more Data quality checks
Click to learn more Reproducibility
Click to learn more
Click to learn more Data quality checks
Click to learn more Reproducibility
Click to learn more
This section provides an overview of the complete HBCD processing workflows for both tabulated data and file-based data, detailing key processing steps, data storage locations (on S3 and other systems), and the responsible teams (see HDCC Structure & Organizational Charts).
| Term | Definition |
|---|---|
| Tabulated data | In standardized HBCD table format, includes behavior & biology, demographics, visit data, and tabulated derivatives. See Data Structure Overview on the main Docs site for an overview of tabulated vs. file-based data. |
| File-based data | In varied formats, includes raw BIDS and processed derivatives for MRI, MRS, EEG, and wearable sensor data. See Data Structure Overview on the main Docs site for an overview of tabulated vs. file-based data. |
| Release Candidate ID | The anonymized ID that will be used as the BIDS subject label in any public releases. |
| DCCID and/or Candidate ID | The original BIDS participant ID prior to de-identification (e.g. sub-1234 where 1234 is the DCCID) in LORIS and other internal data sources. |
| PSCID | Additional ID used in LORIS and during data collection. This ID begins with a five character sequence where the first two characters indicate participant status and the last three characters indicate the recruitment site. |
| de-identification/de-id | The process/outputs associated with replacing DCCIDs/PSCIDs with Release Candidate IDs. |
| re-identification/re-id | The process/outputs associated with replacing Release Candidate IDs with DCCIDs |
| SCE | Secure computing environment at the UMN Health Sciences Technology Office |
| Third party | Refers to external organizations or companies that provide proprietary assessments, scoring tools, or data systems used to collect standardized behavioral, cognitive, and developmental data across study sites |
| Post-processing pipelines, BIDS Apps | Terms used to denote pipelines whose goal is to take imaging, eeg, or other data organized in BIDS and run numerical algorithms to create outputs that can be used for further processing or for statistical analyses. The outputs of these pipelines are referred to as derivatives or imaging-derived phenotypes depending on the context. |
| derivatives | Any files produced by a post-processing pipeline. In other words, the outputs of containerized pipelines or BIDS Apps (such as Nibabies) that are run in CBRAIN. |
| Imaging-derived phenotypes | Scalar values that are output from a pipeline (such as brain volume) that can be concatenated across subjects and used for statistical analyses |
S3 Bucket Descriptions🔗
| Diagram Key | S3 Object s3://midb-hbcd* |
Description |
|---|---|---|
| Main PR | -main-pr/ |
LORIS production bucket that receives all tabulated and file-based data for the full HBCD study prior to staging and Lasso ingestion, including:
|
| De-ID | -main-deid/ |
De-identified/anonymized data (Release Candidate IDs used for subject labels), including:
|
| De-Id-List | -main-pr-deidentification-list/ |
ID mapping file release_identifiers_YYYYMMDD.csv, re-created daily, showing relationships between the various ID types used in HBCD (e.g. contains de-identified participant list information used for de-identification).
|
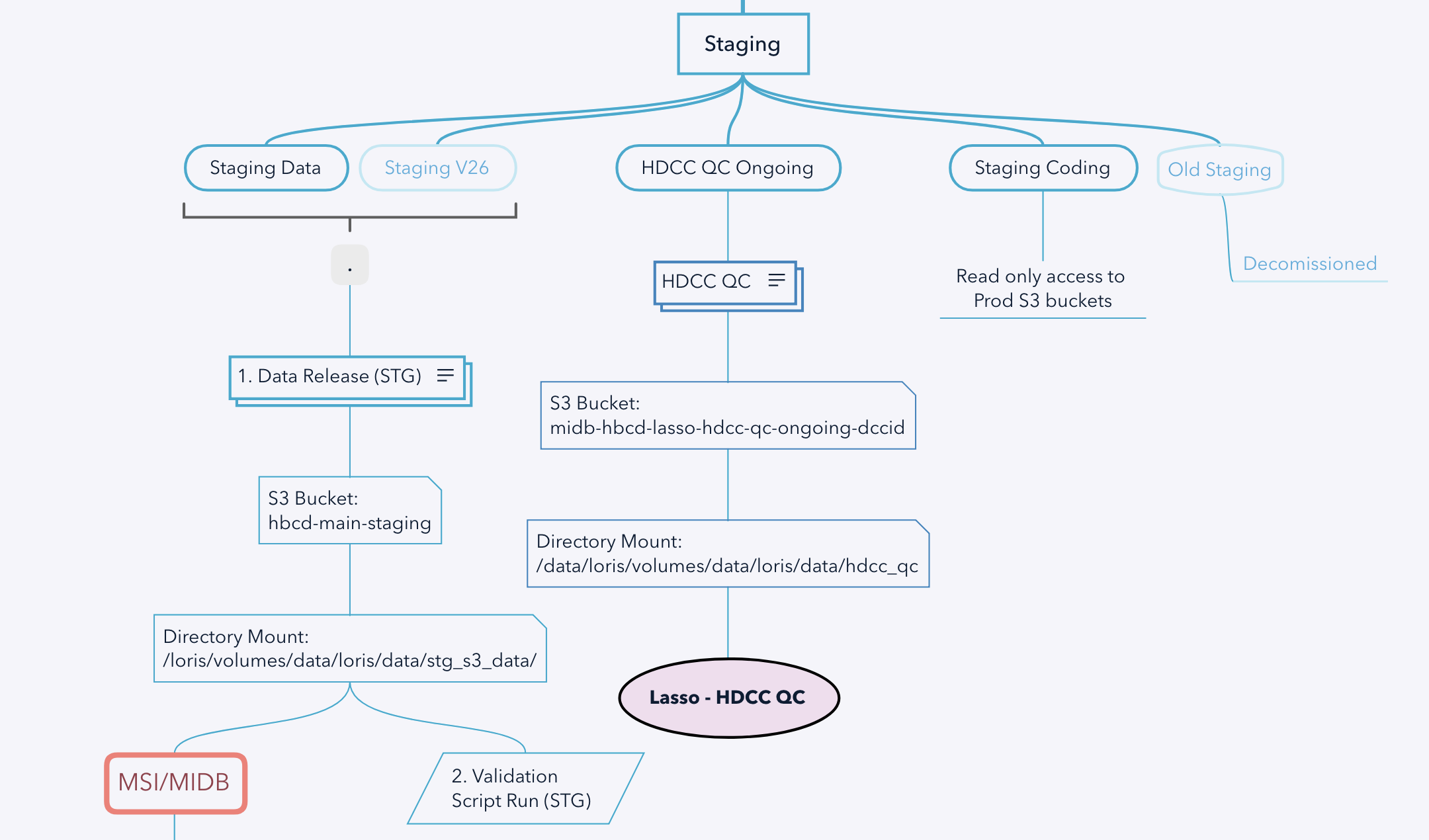
| Lasso Staging | -staging/ |
Where LORIS deposits tabulated data after running data release script for each BR |
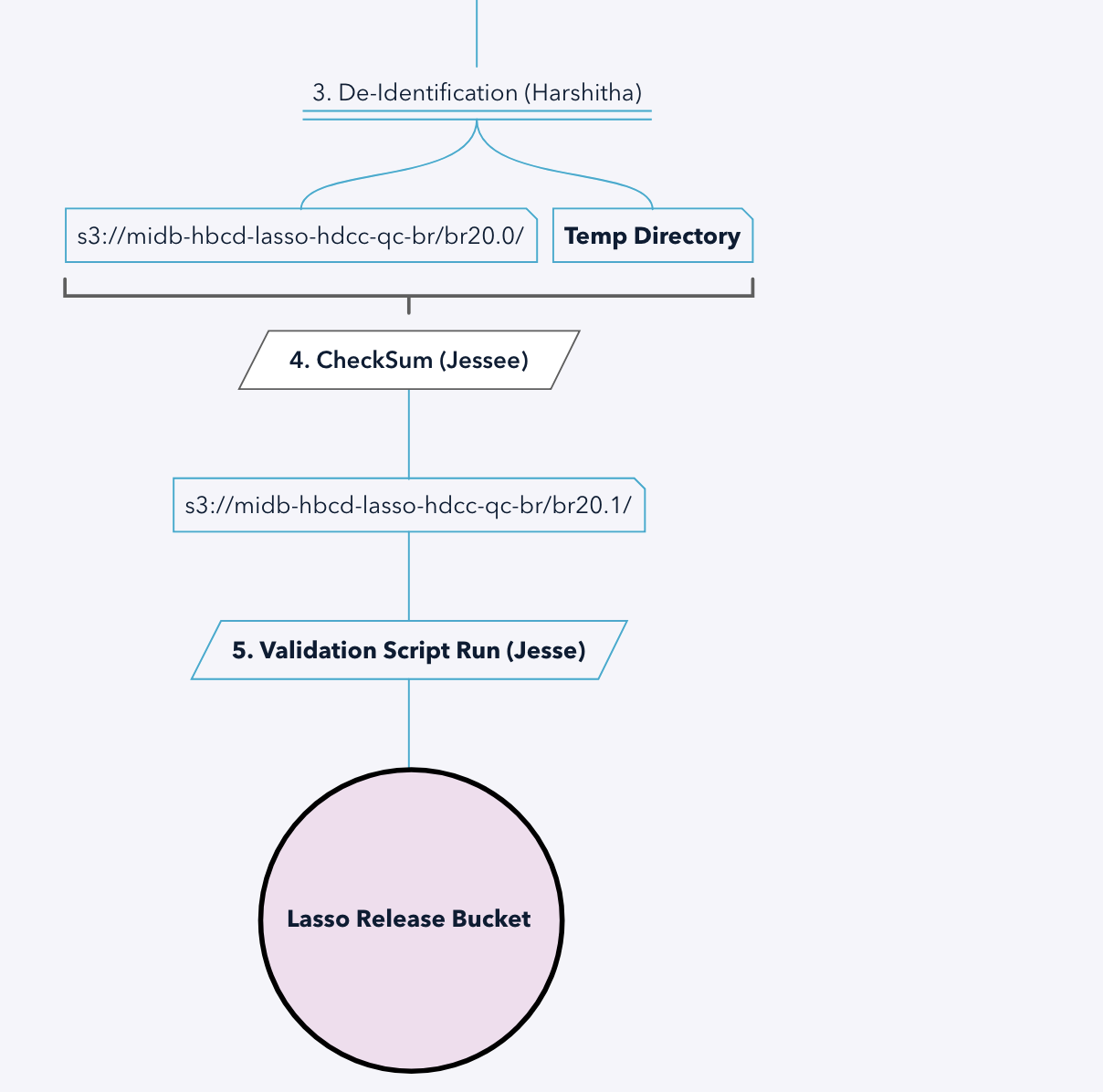
| Lasso PR* | -lasso-hdcc-qc-br/ |
Lasso Pre-Release contains release version-specific data (de-identified) housed under br{BETA RELEASE#}/hbcd/ to be ingested into Lasso |
| QC Env* | -lasso-hdcc-qc-ongoing-dccid/ |
Lasso HDCC environment for ongoing QC; mimics the structure of the release data deposits, but excludes the br{BETA RELEASE#} prefix. The data contains DCCIDs only and is updated with both release and non-release main study participant data regularly, including:
|
| JCVI | -ucsd-main-pr-dicoms/ |
JCVI DICOMs and raw data QC results. |
| MRS BIDS | -main-pr-mrs/ |
MRS data post-BIDS conversion. |
| Sandbox | main-sb/ |
LORIS Bucket for non-production system to test data flows on pilot data |
HBCD VM Staging🔗
See the full diagram for HBCD Staging VMs and associated buckets here. For the Data Release stream, de-identified data flows into the older BR directory (after a copy is pushed to the final BR), and checksum is run at this stage between the previous and new BR data.